Notes to self, 2014
2014-11-17 - photo exif timestamp / filesystem mtime
Sometimes, after a stray copy operation, your filesystem times may reflect the time the files were copied instead of when the file was actually last altered.
For example this image folder here:
$ ls -l phone2013 total 320856 -rw-rw-r-- 1 walter walter 1524591 nov 17 21:52 2012-10-28 08.54.58.jpg -rw-rw-r-- 1 walter walter 1534840 nov 17 21:52 2012-10-28 08.55.04.jpg -rw-rw-r-- 1 walter walter 1635908 nov 17 21:52 2012-10-28 08.55.09.jpg ... -rw-rw-r-- 1 walter walter 1600504 nov 17 21:52 2013-10-22 11.54.25.jpg -rw-rw-r-- 1 walter walter 1478624 nov 17 21:52 2013-10-22 12.04.57.jpg
This time, the filename happens to hold the date (Samsung phone),
but many other times, the filenames will look like IMG_7897.JPG
or similar.
Can we restore the filesystem modification (creation) times from the timestamp which is contained in the JPEG?
Yes we can, using exiftran(1) and a small littly utility
I hacked up.
Let's see how that works:
$ exifdate2fs.sh -A ./phone2013/2013-10-21 10.40.03.jpg: 201310211040.02 ./phone2013/2012-10-28 08.55.29.jpg: 201210280855.28 ./phone2013/2013-03-09 15.07.10.jpg: 201303091507.09 ... ./phone2013/2013-03-09 14.03.03.jpg: 201303091403.01 ./phone2013/2013-10-21 10.41.39.jpg: 201310211041.38 ./phone2013/: 201310221204.56
Right on. That exifdate2fs -A iterated over all JPG files in .
and below and fixed the times. And now things look like they should, including the directory itself.
$ ls -l total 44 drwxrwxr-x 2 walter walter 40960 okt 22 2013 phone2013 $ ls -l phone2013/ total 320856 -rw-rw-r-- 1 walter walter 1524591 okt 28 2012 2012-10-28 08.54.58.jpg -rw-rw-r-- 1 walter walter 1534840 okt 28 2012 2012-10-28 08.55.04.jpg -rw-rw-r-- 1 walter walter 1635908 okt 28 2012 2012-10-28 08.55.09.jpg ... -rw-rw-r-- 1 walter walter 1600504 okt 22 2013 2013-10-22 11.54.25.jpg -rw-rw-r-- 1 walter walter 1478624 okt 22 2013 2013-10-22 12.04.57.jpg
Get it here while it's hot: exifdate2fs.sh (view)
2014-10-17 - python / ctypes / socket / datagram
So, I was really simply trying to figure out why talking to my OpenSIPS instance over a datagram unix socket failed. If I had bothered to check the server logs, I would immediately have seen that it was a simple stupid permission issue.
Instead, I ended up reimplementing recvfrom and sendto
in Python using the ctypes library. Which was completely useless,
since Python socket.recvfrom and socket.sendto already
work properly.
To let the time spent on that not go to a complete waste, I give you (and myself) an example of ctypes usage.
For those who don't know: the ctypes library allows you to
call C library functions from Python directly. The lib handles most things for you,
but you need to do some manual labour when dealing with structs and pointers.
The following snippet might provide a few pointers (hehe) on how to proceed.
For the record, it was these two that I was aiming for:
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,
struct sockaddr *src_addr, socklen_t *addrlen);
ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,
const struct sockaddr *dest_addr, socklen_t addrlen);
The Python code; starts with a bunch of imports.
# vim: set ts=8 sw=4 sts=4 et ai:
import ctypes
import os
import socket
import sys
libc = ctypes.CDLL('libc.so.6')
Defines and structs.
I called sin_family sa_family to get
duck-typing in from_sockaddr.
def SUN_LEN(path):
"""For AF_UNIX the addrlen is *not* sizeof(struct sockaddr_un)"""
return ctypes.c_int(2 + len(path))
UNIX_PATH_MAX = 108
PF_UNIX = socket.AF_UNIX
PF_INET = socket.AF_INET
class sockaddr_un(ctypes.Structure):
_fields_ = [("sa_family", ctypes.c_ushort), # sun_family
("sun_path", ctypes.c_char * UNIX_PATH_MAX)]
class sockaddr_in(ctypes.Structure):
_fields_ = [("sa_family", ctypes.c_ushort), # sin_family
("sin_port", ctypes.c_ushort),
("sin_addr", ctypes.c_byte * 4),
("__pad", ctypes.c_byte * 8)] # struct sockaddr_in is 16 bytes
Converting to and from those structs.
Before calling recvfrom we create a sockaddr
with address unset. The recvfrom call will fill it.
# For compatibility with Python-socket, AF_UNIX uses a string address
# and AF_INET uses an (ip_address, port) tuple.
def to_sockaddr(family, address=None):
if family == socket.AF_UNIX:
addr = sockaddr_un()
addr.sa_family = ctypes.c_ushort(family)
if address:
addr.sun_path = address
addrlen = SUN_LEN(address)
else:
addrlen = ctypes.c_int(ctypes.sizeof(addr))
elif family == socket.AF_INET:
addr = sockaddr_in()
addr.sa_family = ctypes.c_ushort(family)
if address:
addr.sin_port = ctypes.c_ushort(socket.htons(address[1]))
bytes_ = [int(i) for i in address[0].split('.')]
addr.sin_addr = (ctypes.c_byte * 4)(*bytes_)
addrlen = ctypes.c_int(ctypes.sizeof(addr))
else:
raise NotImplementedError('Not implemented family %s' % (family,))
return addr, addrlen
def from_sockaddr(sockaddr):
if sockaddr.sa_family == socket.AF_UNIX:
return sockaddr.sun_path
elif sockaddr.sa_family == socket.AF_INET:
return ('%d.%d.%d.%d' % tuple(sockaddr.sin_addr),
socket.ntohs(sockaddr.sin_port))
raise NotImplementedError('Not implemented family %s' %
(sockaddr.sa_family,))
The two functions I was aiming for.
Observe how only addr and (in the case of recvfrom)
addrlen needs extra ctypes.byref love to
ensure that the data is passed through a pointer.
# ssize_t sendto(int sockfd, const void *buf, size_t len, int flags,
# const struct sockaddr *dest_addr, socklen_t addrlen);
def sendto(sockfd, data, flags, family, address):
buf = ctypes.create_string_buffer(data)
dest_addr, addrlen = to_sockaddr(family, address)
ret = libc.sendto(sockfd, buf, len(data), flags,
ctypes.byref(dest_addr), addrlen)
return ret
# ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags,
# struct sockaddr *src_addr, socklen_t *addrlen);
def recvfrom(sockfd, length, flags, family):
buf = ctypes.create_string_buffer("", length) # no need to zero it
src_addr, addrlen = to_sockaddr(family)
ret = libc.recvfrom(sockfd, buf, length, flags,
ctypes.byref(src_addr), ctypes.byref(addrlen))
assert ret == len(buf.value)
return buf.value, from_sockaddr(src_addr)
An example echo server, using recvfrom and sendto.
Nothing special from now on.
def echo_server(sock, af, bindaddr):
sock.bind(bindaddr)
try:
while True:
data, addr = recvfrom(sock.fileno(), 4096, 0, af)
mangled = ''.join(reversed([i for i in data]))
print 'Got %r from %r, sending response %r' % (data, addr, mangled)
sendto(sock.fileno(), mangled, 0, af, addr)
finally:
if af == socket.AF_UNIX:
os.unlink(bindaddr)
sock.close()
An example client for that echo server.
def send_server(sock, af, bindaddr, addr):
sock.bind(bindaddr)
try:
while True:
try:
data = raw_input('>> ')
except EOFError:
sys.stdout.write('\r')
break
sendto(sock.fileno(), data, 0, af, addr)
data, addr = recvfrom(sock.fileno(), 4096, 0, af)
print 'Got %r from %r' % (data, addr)
finally:
if af == socket.AF_UNIX:
os.unlink(bindaddr)
sock.close()
It wouldn't be a real example if you cannot run it.
if __name__ == '__main__':
if len(sys.argv) in (3, 4) and sys.argv[1] == '-U':
sock = socket.socket(PF_UNIX, socket.SOCK_DGRAM)
af = socket.AF_UNIX
bindaddr = sys.argv[2]
addr = (len(sys.argv) == 4) and sys.argv[3] or None
elif len(sys.argv) in (3, 4) and sys.argv[1] == '-I':
sock = socket.socket(PF_INET, socket.SOCK_DGRAM)
af = socket.AF_INET
if len(sys.argv) == 3:
bindaddr = ('0.0.0.0', int(sys.argv[2]))
addr = None
else:
bindaddr = ('0.0.0.0', 0)
addr = (sys.argv[2], int(sys.argv[3]))
else:
print 'Usage:'
print ' python ctypes-dgram.py -U ./echosock'
print ' echo hello unix socket |'
print ' python ctypes-dgram.py -U ./mysock ./echosock'
print 'or:'
print ' python ctypes-dgram.py -I 1234 # echoport'
print ' echo hello internet |'
print ' python ctypes-dgram.py -I 127.0.0.1 1234'
sys.exit(1)
if addr:
send_server(sock, af, bindaddr, addr)
else:
echo_server(sock, af, bindaddr)
And the invocation looks like this:
$ python ctypes-dgram.py -U ./echosock Got 'Hello World!' from './mysock', sending response '!dlroW olleH'
$ python ctypes-dgram.py -U ./mysock ./echosock >> Hello World! Got '!dlroW olleH' from './echosock'
I did use ctypes in a useful manner previously, in
pysigset.
Observe that this works for any C library, not just libc.
This may save you from having to code a C wrapper one day.
And a final note to self: remember to check the logs!
2014-09-10 - rsyslog / cron / deleting rules
Syslog generally works fine as it is, so I don't need to poke around in it often. That also means that I forget how to tweak it.
How did you move those every-5-minutes cron jobs out of /var/log/syslog?
The rules (selection + action) look like this in the Debian default config:
*.*;auth,authpriv.none -/var/log/syslog #cron.* /var/log/cron.log
The manual has this to say about it:
You can specify multiple facilities with the same priority pattern in one statement using the comma (
,) operator. You may specify as much facilities as you want. Remember that only the facility part from such a statement is taken, a priority part would be skipped.Multiple selectors may be specified for a single action using the semicolon (
;) separator. Remember that each selector in the selector field is capable to overwrite the preceding ones. Using this behavior you can exclude some priorities from the pattern.
I.e. for our needs, the following two are equivalent:
*.*;auth,authpriv,cron.none -/var/log/syslog cron.* /var/log/cron.log
And:
*.*;auth.none;authpriv.none;cron.none -/var/log/syslog cron.* /var/log/cron.log
Secondly, my cron jobs never crash the system, so I add a minus (-)
before the /var/log/cron.log as well.
Can we not touch the default rsyslog.conf and use only additional files in rsyslog.d?
No. Apparently you cannot overwrite or delete older rules with rsyslog. As CCSF writes:
rsyslog has introduced the use of a configuration directory
/etc/rsyslog.d. File with the extension .conf in this directory are included byrsyslog.conf. The include happens between the modules/templates section and the rules section. Thus the included files can have modules and templates as well as rules. Create a.conffile in this directory if possible and avoid modifying rsyslog.conf itself. Note that this is only possible if you want to add modules and rules. If you need to modify existing rules or delete current modules you must still modifyrsyslog.conf.
That confirms my suspicions. Unfortunately. We still need to go into
rsyslog.conf to add cron.none (and
local0..7.none for the machines that use that). If you have any
tips/clues, please tell me.
Update 2015-04-17
Apparently there is a way, at least with recent-ish rsyslog versions like 5.8.
Put this in a file in /etc/rsyslog.d/:
cron.* /var/log/cron.log & ~ local3.* /var/log/local3-stuff.log & ~
The & ~ will discard the last matched line so it
doesn't show up in any further logs.
Another tip, if you want to combine multiple property based filters: you can't. But you can use the single line RainerScript filters, like this:
if $syslogfacility-text == 'local0' and \ $msg contains 'SPECIAL' then \ /var/log/rare-and-special.log local0.* /var/log/local0.log & ~
2014-09-06 - daemon reparented / init --user
While I was battling an obscure Ubuntu shutdown issue — more about that
later — I noticed that daemonized jobs started from my X session
were not reparented to PID 1 init, but to a custom
init --user, owned by me.
What? I cannot start daemon that outlives my X session?
That's right, I cannot. Check this out:
$ sh -c 'sleep 61 &' $ ps faxu | egrep 'init|sleep 61' root 1 ... /sbin/init walter 2198 ... \_ init --user walter 6673 ... | | \_ egrep --color=auto init|sleep 61 walter 6671 ... \_ sleep 61
Okay then. What is this black magic?
It's apparently caused by PR_SET_CHILD_SUBREAPER; available
through prctl since Linux kernel 3.4. Ubuntu added that
in Raring (13.04), according to
Raring Upstart User Sessions, PID tracking.
Can I work around that?
Short answer: no, the PR_SET_CHILD_SUBREAPER interface
allows a single process to enable or disable the feature, but not
for someone else to disable it.
Long answer: yes, but only if we alter the subreaper state of the User Session init; like this:
$ sudo gdb `which init` -p `pgrep -xf 'init --user'` \
-batch -ex 'call prctl(36,0,0,0,0)'
Password:
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
0x00007f3b7a6848c3 in __select_nocancel () at ../sysdeps/unix/syscall-template.S:81
81 ../sysdeps/unix/syscall-template.S: No such file or directory.
$1 = 0
$ sh -c 'sleep 61 &'
$ ps faxu | egrep 'init|sleep 61'
root 1 ... /sbin/init
walter 2198 ... \_ init --user
walter 6986 ... | | \_ egrep --color=auto init|sleep 61
walter 6957 ... | \_ man 5 init
walter 6984 ... sleep 61
Hah! sleep 61 is now owned by PID 1 directly.
By the way, reverting that hack is as easy as changing the second argument
to prctl from 0 to 1.
So, apparently I really am barred from creating PID 1 owned daemons unless
I hack the init --user process.
That does raise the question how initctl daemons are spawned, but that's done
by asking /sbin/init to do that for us:
# netstat -lnAunix | grep '/com/ubuntu/upstart$'
unix 2 [ ACC ] STREAM LISTENING 8049 @/com/ubuntu/upstart
# strace start cups
...
connect(3, {sa_family=AF_LOCAL, sun_path=@"/com/ubuntu/upstart"}, 22) = 0
...
cups start/running, process 6883
Yuck! Did I mention I'm glad we're moving to systemd?
2014-09-05 - git / resetting merges
Today's git question: does git reset undo a merge or only parts of it?
TL;DR: It undoes the entire merge.
If you think about it logically, it must, since an object describes the entire state of the repository. But it can feel awkward and unexpected that older items than the object that we're resetting to, are removed as well.
Let's just try it. Set up a repository with two branches:
$ git init Initialized empty Git repository in /home/walter/Junk/gittest/.git/ $ cat > document.txt << EOF This is a pretty short and quite manageable document. EOF $ git add document.txt; git commit -m 'initial commit' [master (root-commit) 3777fb9] initial commit 1 file changed, 9 insertions(+) create mode 100644 document.txt $ git checkout -b long Switched to a new branch 'long' $ sed -i -e 's/short/long/' document.txt $ git commit document.txt -m 's/short/long/' [long 6e201e1] s/short/long/ 1 file changed, 1 insertion(+), 1 deletion(-) $ git checkout master Switched to branch 'master' $ sed -i -e 's/document./bit of documentation./' document.txt $ git commit document.txt -m 'Clarify meaning of doc' [master 1bd94ee] Clarify meaning of doc 1 file changed, 1 insertion(+), 1 deletion(-) $ git checkout long Switched to branch 'long' $ sed -i -e 's/long/longer/' document.txt; git commit document.txt -m 's/long/longer/' [long 0491d3f] s/long/longer/ 1 file changed, 1 insertion(+), 1 deletion(-)
The log of long looks like this:
$ git log --pretty=oneline 4e7d24196eb624df2eed3977c61bea3efb5e1af7 s/long/longer/ 6e201e1786c0997a13f3cc2842df71e6f01aae06 s/short/long/ 3777fb93ec12e48abc7899066c75122926f5f1e6 initial commit
And the log of master now looks like this:
$ git checkout master Switched to branch 'master' $ git log --pretty=oneline 1bd94ee1c399139e8851acaefcc4bd968bd50002 Clarify meaning of doc 3777fb93ec12e48abc7899066c75122926f5f1e6 initial commit
Let's merge long into it.
$ git merge long Auto-merging document.txt Merge made by the 'recursive' strategy. document.txt | 2 +- 1 file changed, 1 insertion(+), 1 deletion(-) $ git log --pretty=oneline eea3354f4592175dbbbec321678a8bf9be9b9296 Merge branch 'long' 4e7d24196eb624df2eed3977c61bea3efb5e1af7 s/long/longer/ 1bd94ee1c399139e8851acaefcc4bd968bd50002 Clarify meaning of doc 6e201e1786c0997a13f3cc2842df71e6f01aae06 s/short/long/ 3777fb93ec12e48abc7899066c75122926f5f1e6 initial commit
So, the question was: when we reset to 1bd94ee ("Clarify meaning of doc"),
do we keep 6e201e1 ("s/short/long/") or not?
The answer: git reset will get you out of the entire merge.
$ git reset --hard 1bd94ee1c399139e8851acaefcc4bd968bd50002 HEAD is now at 1bd94ee Clarify meaning of doc $ git log --pretty=oneline 1bd94ee1c399139e8851acaefcc4bd968bd50002 Clarify meaning of doc 3777fb93ec12e48abc7899066c75122926f5f1e6 initial commit
2014-08-15 - apt / hold upgrades / dependencies
Recently I wrote about cherry picking upgrades. Sometimes you'll want to do the inverse.
For that purpose there exists apt-mark hold (and its counterpart apt-mark unhold).
For example, you may to delay the mysql upgrade I mentioned, for now. In that case you do:
# apt-mark hold mysql-client-5.5 mysql-common mysql-server-5.5 mysql-server-core-5.5
Now you can apt-get upgrade all the other packages while the mysql packages
stay on hold. Note that these are shown in the held list every time you
run upgrade, so you won't forget about them.
# apt-get upgrade ... The following packages have been kept back: mysql-client-5.5 mysql-common mysql-server-5.5 mysql-server-core-5.5
2014-08-14 - squirrelmail / clicking on empty subject
SquirrelMail on Debian/Wheezy (2:1.4.23~svn20120406-2) stopped
showing (none) for e-mails that lack a subject. Now I cannot
open any subject-less mail because there is nothing to click on.
The quick fix:
--- /usr/share/squirrelmail/functions/mailbox_display.php.orig 2014-08-15 10:37:37.000000000 +0200
+++ /usr/share/squirrelmail/functions/mailbox_display.php 2014-08-15 10:38:27.000000000 +0200
@@ -268,6 +268,9 @@ function printMessageInfo($imapConnectio
$title = str_replace('"', "''", $title);
$td_str .= " title=\"$title\"";
}
+ if (!$subject) {
+ $subject = '(none)';
+ }
$td_str .= ">$flag$subject$flag_end</a>$bold_end";
echo html_tag( 'td', $td_str, 'left', $hlt_color );
break;
2014-06-26 - compose key / irony punctuation / x11
Transcript follows:
[him] did I mention I'll be off from work earlier today because I'm having dinner with friends. I'll be off earlier today because I'm having dinner with friends. [me] where did you say you were going? [him] I'll be having dinner at the Grand Cafe
Apparently the irony was lost on him. I should've used emoticons.
But! Instead of emoticons, one may also use the irony punctuation: ⸮
Let's retry that.
[me] where did you say you were going⸮ [him] ha ha funny guy..
Excellent! So, where is that thing located on the keyboard?
The interrobang (‽) can be composed using the compose key (combine key) + exclamation mark (!) + question mark (?). The irony punctuation however, is not in the list[1].
Adding it goes like this:
# cat >> ~/.XCompose << EOF include "%L" # import the default Compose file for your locale <Multi_key> <slash> <question> : "⸮" U2E2E # REVERSED QUESTION MARK (IRONY PUNCTUATION) EOF # echo 'export GTK_IM_MODULE="xim" # Compose key stuff' >> ~/.profile # # (lastly: restart your X session)
Now you can start being ironic and annoying more often. Just hit: compose key + slash (/) + question mark (?)
[1] /usr/share/X11/locale/en_US.UTF-8/Compose
Update 2014-08-15
Unfortunately the xim
input
method has issues with the Chromium Browser.
You may want to disable this stuff for now.
Also, apparently you should not edit ~/.profile but
put the following in ~/.xinputrc:
# im-config(8) generated on Thu, 07 Aug 2014 08:26:49 +0200 run_im xim # im-config signiture: 89512b7941127eeda7d3e3ac5703f05e -
Update 2014-11-11
As of chromium browser version 38.0.2125.111-0ubuntu0.14.04.1.1061 this problem is fixed.
2014-06-09 - apt / cherry-pick upgrades / dependencies
So, doing an apt-get upgrade on a Debian or Ubuntu machine
sometimes does more than you want at once.
See this upgrade example I encountered just now:
# apt-get upgrade ... The following packages will be upgraded: curl dpkg ifupdown iproute libcurl3 libcurl3-gnutls libgnutls26 libmysqlclient18 libsnmp-base libsnmp15 libssl1.0.0 libxml2 linux-firmware linux-generic-lts-quantal mysql-client-5.5 mysql-client-core-5.5 mysql-common mysql-server mysql-server-5.5 mysql-server-core-5.5 openssh-client openssh-server openssl tzdata update-manager-core whoopsie 26 upgraded, 0 newly installed, 0 to remove and 2 not upgraded. Need to get 63.0 MB/63.0 MB of archives.
I do want to upgrade the mysql, but I don't want to combine that with the other upgrades. Why? Because of the install cycle:
- Download
- Unpack/prepare
- Setup
During the prepare cycle, some daemons are stopped and they are first started during the setup cycle. That means that the mysql server may be down for a longer period of time than necessary.
To mitigate that, we can attempt to upgrade only the mysql-server package:
# apt-get install mysql-server ... The following packages will be upgraded: mysql-server
However, that includes only the mysql-server package and not the related packages (libs, core, mysql-client). That would be a bad idea.
So, how do we force it to install only mysql-server and the related packages?
Here, aptitude comes to the rescue:
# echo `aptitude search -F%p '?reverse-depends(mysql-server) ?installed'` adduser debconf libc6 libdbi-perl libstdc++6 libwrap0 lsb-base mysql-client-5.5 mysql-common mysql-server-5.5 mysql-server-core-5.5 passwd perl psmisc upstart zlib1g
Or, better yet:
# echo `aptitude search -F%p '?reverse-depends(mysql-server) ?upgradable'` mysql-client-5.5 mysql-common mysql-server-5.5 mysql-server-core-5.5
That's a much nicer list. Fire away:
# aptitude install '?reverse-depends(mysql-server) ?upgradable' The following packages will be upgraded: mysql-client-5.5 mysql-common mysql-server mysql-server-5.5 mysql-server-core-5.5 5 packages upgraded, 0 newly installed, 0 to remove and 23 not upgraded. ...
Update 2014-08-15
Sometimes you want to do the inverse — skip a bunch of related packages.
Look at: holding/delaying package upgrades
2014-06-08 - vim / position markers
Did you ever wonder what the '<,'> characters mean when you
CTRL-V visual block select text in vim?
For example: you press CTRL-V and select a bit of text. Then type :
(colon). Instead of just the colon, you see: :'<,'>.
You append s/^/#/ hit enter. As requested, the selected block is now
“commented out”.
That's a nice feature, but why the funny characters? In order to understand that,
we remind you of the % (percent sign) that we use to select the
entire file.
Examples:
:%s/[[:blank:]]\+$// to remove all trailing blanks
:%!sort to sort the entire file (you can do this on a CTRL-V selection too)
The percent sign defines the special range everything. The odd
'<,'> combination defines a range between two markers.
Instead of operating on the whole file, vim operates on a range.
When you expanded the CTRL-V selection, you moved the markers to absolute positions
in the file. You can now jump to those positions in command mode using '< and
'>. If the markers are at lines 5 and 9, the range expression would be
as if you had written 5,9.
It gets better. You get custom markers: 26 of them to be exact. Which you can place at will
using m[LETTER]. You jump to those lines using '[LETTER].
Is that useful? Yes. Apart from keeping different editing locations in memory, it can come in handy for large ranges.
It happens now and then that I have to look through a large diff, and I only want to keep
certain portions of it. What I do now, is place a marker using ma and start scrolling.
First when I encounter something I want to keep, I press mb above it.
Next: :'a,'bd and voilà the unneeded stuff is deleted (with d).
Scroll to the first unneeded bits, press ma again and repeat.
2014-06-07 - vim / reformat textwidth 72
My .vimrc usually starts out with this. Syntax highlighting is super,
and my terminals always have a black background. The modeline option enables me
and others to set certain options for certain files only. Like:
{# vim: syntax=htmldjango: #} to mark a .html file as using the
django html syntax instead of regular html syntax.
See also my Inserting vim modelines
tip.
syn on set bg=dark set modeline
Second, since I develop a lot in Python, I enable the vim-flake8 python source code checker plugin:
$ sudo pip install flake8
$ mkdir -p ~/.vim/ftplugin
$ wget -O ~/.vim/ftplugin/ \
https://github.com/nvie/vim-flake8/raw/master/ftplugin/python_flake8.vim
This also requires the following additions to your .vimrc:
" Enable python_flake8 checker filetype plugin indent on " HtmlIndent() always works against me in 2013, disable it autocmd BufEnter *html set indentexpr=
Now you can open any Python .py file and do basic
checks on it by pressing <F7>. In the background it runs
flake8 which will
show you a list of potential problems or code style violations.
Beware! Pressing F7 will save the open file!
Next, we can optionally set global flake8 defaults, like this:
" Not sure about these defaults anymore. They worked for me when moving " to the PEP checker initially. I'll probably go full PEP8 in a while. let g:flake8_ignore="E125,E128"
And then we set project-specific defaults. (My projects directory name
srcelf is a contraction of src and self
to distinguish itself from the ~/src directory where
apt-get source'd (and similar) items go.)
" Bosso-project autocmd BufEnter /home/walter/srcelf/bosso/*py set ts=8 sw=4 sts=4 et ai tw=99|let g:flake8_max_line_length=99 autocmd BufEnter /home/walter/srcelf/bosso/*html set ts=8 sw=4 sts=4 et ai nowrap autocmd BufEnter /home/walter/srcelf/bosso/*xml set ts=8 sw=4 sts=4 et ai " Another-project " ...
Notice how we increase the textwidth to 99 characters for both vim and the flake8 checker.
For Django projects, 79 characters is generally too little. Some projects favor 119 characters. I try to go with 99 whenever possible. It makes code fit on half of my screen and make side-by-side diffs nice and readable.
Alright, we're almost there. Finally on to the topic that I was planning to write about: paragraph reformatting and textwidth.
Paragraph reformatting
You probably know what you can reformat a paragraph in vim with
gq. You select a portion using either CTRL-V and arrows and then
gq or you select the whole file by jumping to top, doing gq
and jumping to the end: gggqG
Unfortunately that will reformat to the current textwidth (99 or 119) which is not recommended. PEP8 says 72 characters. And that is the absolute maximum for longer bits of text.
(Read the column mode simetimes better than widespan article on the c2 Content Creation Wiki for why. It graphically shows how humans are better at reading (or glancing through) column layout than wide pages.)
The fix: tell vim to temporarily switch to 72 character textwidth when doing a reformat. Like this:
vnoremap gq <Esc>:let tw=&tw<CR>:set tw=72<CR>gvgq:let &tw=tw<CR>
Excellent! This makes the CTRL-V-arrows-gq method use a 72 characters limit. Precisely what we need to reformat python docstrings.
On the fly formatting
P.S. Vim can also do reformatting on the fly. That can be useful when writing
.txt documentation. Add this to the tail of your document. The
ugly looking flp= describes what bullet lists are.
-- vim: set tw=71 fo=twan flp=^\\s*\\(\\d\\+\\.\\|[*-]\\)\\s* ai nosi: -- vim: set ts=8 sw=2 sts=2 ei: -- see :help fo-table
Completely unrelated sudo-write trick
P.P.S. Since we're doing command (re)mapping here, we might as well add this useful one. Stolen from Nathan Long's answer to how does the vim write with sudo trick work.
" Allow saving of files as sudo when I forgot to start vim using sudo. cmap w!! w !sudo tee % >/dev/null
2014-05-08 - postgresql / upgrade / ubuntu
I always forget how easy it is to upgrade postgresql on Ubuntu (from 9.1 to 9.3 this time). It seems like a pain to have to manually upgrade the cluster, but when it comes down to it, it's self-documenting and quick.
My shell session basically went like this:
$ sudo apt-get install postgresql-9.3 ... The following extra packages will be installed: postgresql-client-9.3 ... $ sudo /etc/init.d/postgresql stop * Stopping PostgreSQL 9.1 database server [ OK ] * Stopping PostgreSQL 9.3 database server [ OK ]
$ sudo su -l postgres $ pg_upgradecluster Usage: /usr/bin/pg_upgradecluster [OPTIONS] <old version> <cluster name> [<new data directory>] $ pg_upgradecluster 9.1 main Error: target cluster 9.3/main already exists $ pg_dropcluster 9.3 main $ pg_upgradecluster 9.1 main Disabling connections to the old cluster during upgrade... Restarting old cluster with restricted connections... ... Upgrading database some_db... ...
Ok, it wasn't that quick. The analyzing and upgrading took several minutes per database, but it was easy.
... Success. Please check that the upgraded cluster works. If it does, you can remove the old cluster with pg_dropcluster 9.1 main $ logout $ sudo /etc/init.d/postgresql start 9.3 * Starting PostgreSQL 9.3 database server [ OK ] $ sudo netstat -tulpen | grep postg tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN 116 138692 10716/postgres $ test_that_it_works $ sudo su -l postgres $ pg_dropcluster 9.1 main $ logout $ find /etc/postgresql/9.1/ /etc/postgresql/9.1/ $ sudo apt-get remove --purge postgresql-9.1 postgresql-client-9.1
2014-05-07 - openssh / nagle / too much buffering
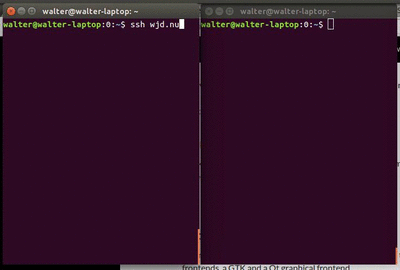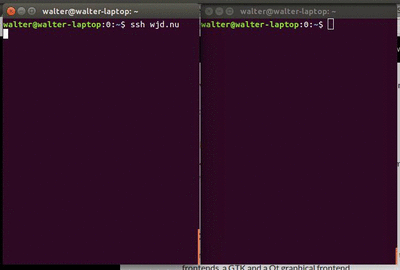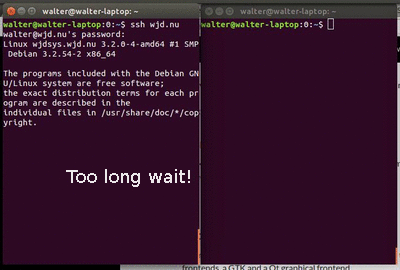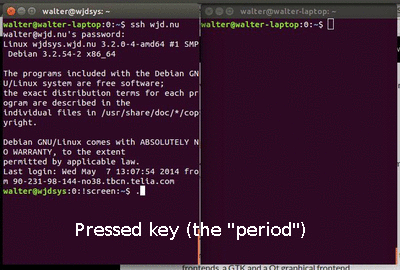
Recently I tried to open a connection to a remote server over SSH at a new location. The connection opened just fine, but it seemed that a few bytes kept getting buffered.
It looked like this first animated gif you see.
After a long wait, you realise that the data you're wating just won't come. First after pressing a key, you get the data.
This isn't workable...
Enumerating the possible culprits, there could really only be the
wifi-nat-modem — a Thomson TG789vn, Telia device — doing extra buffering, possibly conflicting with the
Nagle algorithm (TCP_NODELAY).
Attempt #1: try to switch off any/all buffering options in the modem: the administrator user has too few powers! Boo, Telia.se.
Attempt #2: try to switch off nagle in openssh: eek, there is no option to do that!
Once again, LD_PRELOAD comes to the rescue.
Using this simple custom library, we can override setsockopt — which normally handles
the setting of the TCP_NODELAY option — to do nothing at all.
/* gcc nosetsockopt.c -fPIC -shared -ldl -o nosetsockopt.so
* LD_PRELOAD=./nosetsockopt.so ssh DEST
*/
#include <sys/socket.h>
#include <stdio.h>
int setsockopt(int sockfd, int level, int optname,
const void *optval, socklen_t optlen) {
printf("SETSOCKOPT: %d: %d: %d=%p (%d)\r\n",
sockfd, level, optname, optval, optlen);
return 0;
}
Compiled an ran, we get this extra output:
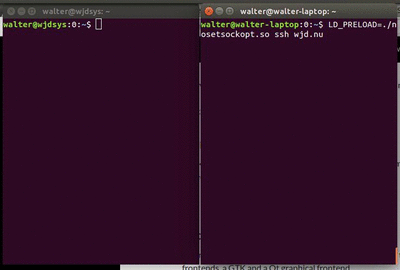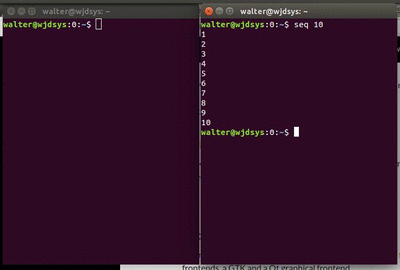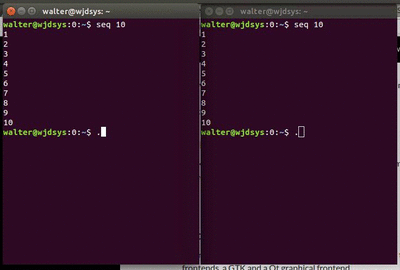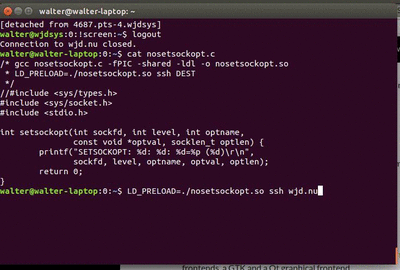
$ gcc nosetsockopt.c -fPIC -shared -ldl -o nosetsockopt.so $ LD_PRELOAD=./nosetsockopt.so ssh dummy@wjd.nu SETSOCKOPT: 3: 1: 9=0x7fffbb2eeef4 (4) dummy@wjd.nu's password: SETSOCKOPT: 3: 6: 1=0x7fffbb2ef188 (4) SETSOCKOPT: 3: 0: 1=0x7fffbb2ef1b8 (4) Linux wjdsys.wjd.nu 3.2.0-4-amd64.. ...
The values we see are as follows:
- The file descriptor is 3.
- The level is either
SOL_SOCKET(1),SOL_TCP(6) orSOL_IP(0). See/etc/protocolsfor those last two. - The corresponding options are:
SO_KEEPALIVE(9),TCP_NODELAY(1) andIP_TOS(1).
Preloading that lib, meant that all those options are not really set anymore. And guess what? The shell behaved normally again. This fixed behaviour is what you see on the right hand side of the second animation. The two windows use a shared screen, so the behaviour should have been identical.
For bonus points, you can alter the lib to call the real setsockopt for all calls except Nagle, as can be seen in this example. But the above version does the trick just fine.
Move the files to /usr/local and put this in your ~/.bash_aliases:
echo "TEMP ALIAS FOR NAGLE" alias ssh='LD_PRELOAD=/usr/local/lib/nosetsockopt.so ssh'
2014-04-26 - ubuntu trusty / git diff color
On my recently upgraded Ubuntu Trusty (14.04) machine, git diff started producing colorized output.
That's nice, but it'd be even nicer if it recognised that I'm using a dark background.
Put this in your ~/.gitconfig. This colorscheme is the one you're
used to from vim.
[color "diff"]
meta = green bold
frag = yellow bold
old = red bold
new = cyan bold
2014-03-22 - zabbix / counting security updates
When you're monitoring security update availability using Zabbix or some other monitoring tool, you'll need a method to discern regular updates from security updates.
I've seen my collegues do this:
$ /usr/lib/update-notifier/apt-check --human-readable | grep security | awk '{print $1}'
But that requires an install of the update-notifier-common package.
(Note the -common. The main package has tons of requirements you don't need.)
In the quest for less dependencies — less installed packages —
I used aptitude to get the info. That one is commonly installed anyway.
$ set +o histexpand # (I hate histexpand because it is impossible to escape properly) $ archive=`sed '/^deb .*security/!d;s/^deb [^ ]* \([^ ]*\) .*/\1/;q' /etc/apt/sources.list` $ /usr/bin/aptitude -F%p search "?upgradable ?archive($archive)" 2>/dev/null </dev/null | wc -l
But the numbers do turn out differently at times:
$ /usr/lib/update-notifier/apt-check --human-readable 163 packages can be updated. 96 updates are security updates.
Versus:
$ for x in wHaTeVeR security; do archive=`sed '/^deb .*'$x'/!d;s/^deb [^ ]* \([^ ]*\) .*/\1/;q' /etc/apt/sources.list` n=`/usr/bin/aptitude -F%p search "?upgradable ?archive($archive)" 2>/dev/null </dev/null | wc -l` echo $n $x done 158 wHaTeVeR 103 security
Is that a problem? The missing 5 items can be explained by the "The following NEW packages will be installed" bit. Those aren't counted.
As for the 7 that I count as security updates while they "aren't",
today I saw an firefox-locale-nl being
classified as security update by apt-check. It itself had no security updates whatsoever.
Then I guess a few extra false positives aren't a problem.
Here's the debian-updates.conf for in your /etc/zabbix/zabbix_agentd.d.
Obviously this works for Ubuntu too.
# Check for debian updates UserParameter=debian_updates[*], aptitude -F%p search "?upgradable ?archive(`sed '/^deb .*$1/!d;s/^deb [^ ]* \([^ ]*\) .*/\1/;q' /etc/apt/sources.list`)" 2>/dev/null | wc -l # Increase the global timeout (unfortunately), or zabbix killing # aptitude will leave a /tmp/aptitude-zabbix.* directory turd every # now and then. Timeout=12
2014-01-15 - python parsestring / silently skips entities
The Python xml.dom.minidom parseString silently skips over
unknown entities.
The only entities it does know, are <, >,
&, ' and " and
of course the numeric entities &#nn; and &#xhh;.
That's obvious, because those are the only ones defined in the XML 1.0 spec.
However, if you're parsing XHTML documents, it's not nice that the entity references to special characters silently get dropped.
Other people have stubled on the same issue, like in parsing xml containing &entities; with minidom and Problem with minidom and special chars in HTML.
The Python minidom documentation for the parse states that “[the]
function will change the document handler of the parser and activate namespace support;
other parser configuration (like setting an entity resolver) must have been done in advance.”
Ah! Something about entities, but no example or further explanation.
So, how do I tell the parseString function what the defined entities are?
That's where minidom_xhtml comes in. The parseStringXHTML function
as defined therein handles adding all the XHTML entities you need into the DOCTYPE declaration.
Download as a package (includes the xhtml*.ent files):
minidom_xhtml-1.tar.gz
(or view the code)
Example usage:
from minidom_xhtml import parseStringXHTML
doc = parseStringXHTML('<html><body>Voilà!</body></html>')
body = doc.getElementsByTagName('body')[0]
print body.firstChild.wholeText.encode('utf-8')
2014-01-13 - bson / json / converter
A simple script to convert BSON data to JSON data: bson2json.py (view)
Example usage:
$ bson2json.py /var/backups/mongodb/all-dbs.mon/graylog2/streams.bson --pretty
[
{
"_id": "506ed227dc1d710c0700000e",
"additional_columns": [],
"alarm_active": true,
"alarm_callbacks": [
"org.graylog2.emailalarmcallback.callback.EmailAlarmCallback",
"org.graylog2.execalarmcallback.callback.ExecAlarmCallback"
],
"alarm_limit": 80,
"alarm_period": 5,
"alarm_timespan": 5,
"created_at": "2012-10-05T12:27:19Z",
...
2014-01-08 - thunderbird / reply / only selected text
Apparently I'm not the only one who randomly selects text as they read. My colleagues complained about this issue too.
If you click Reply in Thunderbird Mail, only the text you recently selected is included in the new message. That's not what I wanted!
Luckily the Mozilla developers realised this too. Go to about:config
and flip the switch.
mailnews.reply_quoting_selection = false