Notes to self, 2013
2013-09-26 - amavis / tag subject / virus
Today we got a suspiciously good looking e-mail in the inbox. Someone who supposedly got a reminder about an unpaid invoice from us.
The mail contained a zip-file with two scans. The first was a PDF, the second was an executable (a virus obviously).
So.. where was the Amavis virus/spam scanner in all this?
Show headers revealed that something was detected:
X-Amavis-Alert: BANNED, message contains .exe,scan2/HP scan scan =?iso-8859-1?Q?HYJKIOPH5600002.=E2=80=AEfdp.exe?=
Then why weren't we informed?
It turns out that Amavis has a $sa_spam_subject_tag configuration option to flag spam,
but there was no such option for the BANNED message.
Here, a quick fix:
--- /usr/sbin/amavisd-new.orig 2013-09-26 08:57:24.961937001 +0200
+++ /usr/sbin/amavisd-new 2013-09-26 09:01:32.193936979 +0200
@@ -1540,7 +1540,7 @@ BEGIN {
);
%subject_tag_maps_by_ccat = (
CC_VIRUS, [ '***INFECTED*** ' ],
- CC_BANNED, undef,
+ CC_BANNED, [ '***VIRUS?*** ' ],
CC_UNCHECKED, sub { [ c('undecipherable_subject_tag') ] }, # not by-recip
CC_SPAM, undef,
CC_SPAMMY.',1', sub { ca('spam_subject_tag3_maps') },
Now these infected messages stand out a little better.
2013-09-24 - gnome-calculator / missing menu
After the upgrade of my desktop to Ubuntu Raring (13.04) my
gnome-calculator's menu bar had become unreachable.
I don't need the menu, except that it went into default BASIC mode. And I need the PROGRAMMING mode.
The configuration seemed to be okay (accessible through gconf-editor):
$ gconftool /apps/gcalctool --dump | grep -B1 -A4 mode
<entry>
<key>mode</key>
<value>
<string>PROGRAMMING</string>
</value>
</entry>
<entry>
<key>modetype</key>
<value>
<string>PROGRAMMING</string>
</value>
</entry>
But that was apparently the old config. The new config is in dconf (accessible through dconf-editor):
$ dconf dump /org/gnome/calculator/ | grep mode button-mode='basic'
Switch that to 'programming' and voilà. Programming mode is back.
What about fixing the problem?
Hacking around in the gnome-calculator source got me lost between
gio GObjects and gtk GtkWindows.
The following tweak made the menu appear, but now the menu items were drawn as separate menus on the menu bar.
diff -pru gnome-calculator-3.8.1/src/gnome-calculator.c gnome-calculator-3.8.1.hacked/src/gnome-calculator.c --- gnome-calculator-3.8.1/src/gnome-calculator.c 2013-04-02 15:25:49.000000000 +0200 +++ gnome-calculator-3.8.1.hacked/src/gnome-calculator.c 2013-09-25 09:12:14.863018583 +0200 @@ -599,6 +599,7 @@ static void calculator_real_startup (GAp _tmp54_ = section; g_menu_append_section (menu, NULL, (GMenuModel*) _tmp54_); gtk_application_set_app_menu ((GtkApplication*) self, (GMenuModel*) menu); + gtk_application_set_menubar ((GtkApplication*) self, (GMenuModel*) menu); gtk_application_add_accelerator ((GtkApplication*) self, "<control>Q", "app.quit", NULL); gtk_application_add_accelerator ((GtkApplication*) self, "F1", "app.help", NULL); gtk_application_add_accelerator ((GtkApplication*) self, "<control>C", "app.copy", NULL);
Getting better results than that is taking too much time. There must be a better way.
The cause of the problem?
 So, it turned out that I didn't have Global menu support. I was aware of that —
my upgrade from 12.04 apparently didn't work flawlessly — but I wasn't aware that that
is unsupported.
So, it turned out that I didn't have Global menu support. I was aware of that —
my upgrade from 12.04 apparently didn't work flawlessly — but I wasn't aware that that
is unsupported.
Mr. Jojo Yee's Tips and Tricks for Ubuntu after Installation [Ubuntu 12.04 to 13.04] finally revealed the fix. See the image to the right which shows the difference between having and not having the "Global menu".
The global menu could be restored like this:
$ sudo apt-get install indicator-appmenu ... The following NEW packages will be installed: appmenu-gtk appmenu-gtk3 appmenu-qt appmenu-qt5 indicator-appmenu libdbusmenu-qt5
And, there is a project going on that should make it easier for people to switch
between the global menu and not. See:
Ubuntu's new Enhanced Menu project
Improve Unity Global Menu
“This [feature enhancement] isn't fixed in 13.04 yet.”
Finally I had enough information to file a decent bug report.
2013-09-16 - teamviewer / without all ia32-libs
A quick rundown on installing TeamViewer without a gazillion ia32-libs.
The problem:
if you attempt to install teamviewer_linux_x64.deb on your 64-bit machine,
the ia32-libs dependency tries to install more than 200 packages.
That not only feels like overkill, it takes a hell of a long time too.
The solution:
alter the dependency list in the .deb and create a small metapackage that
references only the required libs.
What follows, is the steps how.
Fetch the download, and inspect what packages we really need (you can skip the inspection):
$ dpkg -x teamviewer_linux_x64-v8.0.17147.deb tmp
$ cd tmp
$ find . -type f | while read -r x
do word=`test -f "$x" && file "$x" | sed -e 's/^[^:]*: //;s/ .*//'`
test "$word" = ELF && ldd "$x"
done | grep not\ found | sort -u
...
libwine.so.1 => not found
libX11.so.6 => not found
libXdamage.so.1 => not found
libXext.so.6 => not found
libXfixes.so.3 => not found
...
$ cd ..
After installing the following list, only libwine.so.1 would still say "not found"
(which is okay, because it's in the package):
libc6:i386 libgcc1:i386 libx11-6:i386 libxau6:i386 libxcb1:i386 libxdamage1:i386 libxdmcp6:i386
libxext6:i386 libxfixes3:i386 libxtst6:i386
Unfortunately, that was not enough. The “fixme:dbghelp:elf_search_auxv can't find symbol in module”
and “Access violation at 0x7d8ed1b8: Illegal read operation at 0x0000005C (Exception Code: 0xC0000005)”
errors when running, turned out to require these two too:
libfontconfig1:i386 libfreetype6:i386
Create a metapackage to hold the i386 dependencies. dpkg refuses
to add the :i386 variants to the dependency list directly
(a value different from 'any' is currently not allowed).
$ mkdir -p tmp2/DEBIAN $ cat >tmp2/DEBIAN/control <<EOF Package: teamviewer-i386 Version: 8.0.17147 Section: non-free/internet Priority: optional Architecture: i386 Multi-Arch: foreign Depends: libc6, libgcc1, libx11-6, libxau6, libxcb1, libxdamage1, libxdmcp6, libxext6, libxfixes3, libxtst6, libfontconfig1, libfreetype6 Maintainer: Yourself <root@localhost> Description: TeamViewer 32-bit dependencies. EOF
$ dpkg -b tmp2 teamviewer-i386:i386.deb dpkg-deb: building package `teamviewer-i386:i386' in `teamviewer-i386:i386.deb'.
Update the original teamviewer package dependency list:
$ dpkg --control teamviewer_linux_x64-v8.0.17147.deb tmp/DEBIAN $ grep ^Depends: tmp/DEBIAN/control Depends: bash (>= 3.0), libc6-i386 (>= 2.4), lib32asound2, lib32z1, libxext6, ia32-libs
$ sed -i -e 's/ia32-libs/teamviewer-i386/' tmp/DEBIAN/control $ grep ^Depends: tmp/DEBIAN/control Depends: bash (>= 3.0), libc6-i386 (>= 2.4), lib32asound2, lib32z1, libxext6, teamviewer-i386
$ dpkg -b tmp teamviewer_linux_x64-v8.0.17147-custom.deb dpkg-deb: building package `teamviewer' in `teamviewer_linux_x64-v8.0.17147-custom.deb'.
Time to rock:
$ sudo dpkg -i teamviewer-i386.deb ... $ sudo apt-get -f install ... The following NEW packages will be installed: libexpat1:i386 libfontconfig1:i386 libfreetype6:i386 libx11-6:i386 libxau6:i386 libxcb1:i386 libxdamage1:i386 libxdmcp6:i386 libxext6:i386 libxfixes3:i386 libxtst6:i386
Ah, not 220 packages, but only 11. Much better!
$ sudo dpkg -i teamviewer_linux_x64-v8.0.17147-custom.deb ... $ sudo apt-get -f install ...
Profit. A system without hundreds of unused 32-bits libs.
Now if someone can tell me how to fix this, it'd be nice:
$ dpkg-query --show --showformat='${status} ${package}\n' | grep teamviewer-i386
install ok installed teamviewer-i386
$ dpkg -L teamviewer-i386
Package `teamviewer-i386' is not installed.
Use dpkg --info (= dpkg-deb --info) to examine archive files,
and dpkg --contents (= dpkg-deb --contents) to list their contents.
Because that's what the nightly /usr/sbin/popularity-contest
calls :-(
2013-09-11 - mysql / count occurrences
Voilà, a MySQL function to count occurrences of a character (or a string of characters).
DROP FUNCTION IF EXISTS OCCURRENCES;
delimiter //
CREATE FUNCTION OCCURRENCES (`needle` VARCHAR(255), `hackstack` TEXT)
RETURNS INT
NOT DETERMINISTIC READS SQL DATA
SQL SECURITY INVOKER
BEGIN
DECLARE `result` INT DEFAULT -1;
DECLARE `pos` INT DEFAULT 0;
DECLARE `skip` INT DEFAULT LENGTH(`needle`);
REPEAT
SET `pos` = (SELECT LOCATE(`needle`, `hackstack`, `pos` + `skip`));
SET `result` = `result` + 1;
UNTIL `pos` = 0 END REPEAT;
RETURN `result`;
END;
//
delimiter ;
Now you can do things like this:
mysql> select occurrences('axa', 'axaxaxa') as how_many_axas;
+---------------+
| how_many_axas |
+---------------+
| 2 |
+---------------+
1 row in set (0.00 sec)
Or, it could be put to useful use in cases like sorting domain names by top level domain first.
See this patch to PowerAdmin 2.1.5 (view) for an example. It fixes a couple of sorting problems, and adds login logging to syslog. The login logging — in turn — can be used to block attempts using fail2ban (view).
2013-09-06 - mysql / datetime / indexes
MySQL has many odd quirks. One that bit us recently was this:
regression: >=mysql-5.4 utf8 collations are marked as not ascii compatible
When using the utf8_unicode_ci collation, datetime column comparisons against
strings would ignore any indexes. The lack of working indexes obviously caused huge performance degradation.
Our bug report was ignored in Februari. Apparently a new bug was opened in March:
Datetime field comparisons do not work properly with utf8_unicode_ci collation
And that was deemed important enough to fix.
Looking at the source of version 5.5.33 I see that the UTF-8
flags are now combined into MY_CS_UTF8MB3_UCA_FLAGS, like already done in 5.6.
In the mean time, those looking for a fix on Ubuntu 12.04 Precise can use the OSSO PPA:
$ sudo add-apt-repository ppa:osso/ppa $ sudo sh -c 'cat >/etc/apt/preferences.d/osso' <<__EOF__ # Decrease prio for all Package: * Pin: release o=LP-PPA-osso Pin-Priority: -10 # Increase prio for mysql* Package: mysql* libmysql* Pin: release o=LP-PPA-osso Pin-Priority: 500 __EOF__
It uses the 5.5.32-0ubuntu0.12.04.1 version as supplied by Ubuntu but patched
with 80_utf8_is_ascii_superset.patch
(view).
I'd love to comment on the bug report that they have probably fixed it, but Oracle made login and password recovery so tedious that I can't. For instance, the recovery e-mail that I requested half an hour ago, still isn't in my inbox.
2013-09-04 - thunderbird / postfix / dkim / invalid body hash
Mozilla Thunderbird uses an odd max line length of 999 + CRLF: 1001 characters. When using DKIM preprocessing, this can result in DKIM validation failure.
To reproduce, we would send a mail that didn't wrap well with line lengths in excess
of 999 characters. Like this mail with 1000 'x' characters:
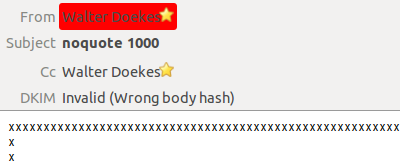
Thunderbird splits that into 999 times 'x', and CRLF and another line with
a single 'x'. However, that first line gets split again.
Turns out Postfix resumed splitting up the lines some more (even though the CRLFs got translated to bare LFs at the end).
In our case, we were using the following setup:
postfix 2.9.6-1~12.04.1
with smtpd_milters = inet:127.0.0.1:54321,
non_smtpd_milters = inet:127.0.0.1:54321
and on localhost, on port 54321 we have:
opendkim 2.6.8-0ubuntu1.0.1
The workaround:
smtp_line_length_limit = 1001
Now the 1000 'x' mail looks like this:
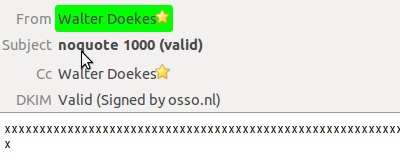
Valid is good!
P.S. That validator is the Thunderbird DKIM Verifier extension.
2013-08-30 - virtualenv / pil pillow mess
Numerous articles have been written about why you want to install
Pillow instead of PIL to get the Python Imaging tools.
Like Problems with PIL? Use Pillow instead!
(Find more by searching for “IOError: decoder zip not available”.)
This note concerns something more insidious: a seemingly broken Pillow installation after the removal of PIL.
~$ mkvirtualenv piltest (piltest)~$ pip install PIL (piltest)~$ pip freeze | grep -i pil PIL==1.1.7
Now this should work:
(piltest)site-packages$ python -c "import Image; im = Image.open('/lib/plymouth/ubuntu_logo.png'); im.load()"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File ".../site-packages/PIL/ImageFile.py", line 189, in load
d = Image._getdecoder(self.mode, d, a, self.decoderconfig)
File ".../site-packages/PIL/Image.py", line 385, in _getdecoder
raise IOError("decoder %s not available" % decoder_name)
IOError: decoder zip not available
Ok. This still doesn't work. This is why the “Problems with PIL? Use Pillow instead!“ articles exist. So. Time to switch to Pillow.
Let's examine what happens when someone comes along and removes the PIL dir by hand.
Perhaps because his pip is so old that it doesn't have an uninstall option.
(piltest)~$ cdsitepackages (piltest)site-packages$ rm -rf PIL (piltest)site-packages$ pip freeze | grep -i pil
Excellent. No PIL installed. Let's resume installing Pillow.
(piltest)site-packages$ pip install Pillow (piltest)site-packages$ pip freeze | grep -i pil Pillow==2.1.0
And yet, stuff is broken.
This works (like documented):
(piltest)site-packages$ python -c "from PIL import Image; im = Image.open('/lib/plymouth/ubuntu_logo.png'); im.load()"
But this — observe the lack of from PIL in the import statement —
seems to work, but breaks.
There is no nice ImportError, but rather a runtime error after loading a file.
(Which of course happens right in the middle of a presentation.)
(piltest)site-packages$ python -c "import Image; im = Image.open('/lib/plymouth/ubuntu_logo.png'); im.load()"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File ".../site-packages/PIL/Image.py", line 2008, in open
raise IOError("cannot identify image file")
IOError: cannot identify image file
That means that a construct like this would fail:
try:
import Image
except ImportError:
from PIL import Image
How did that happen?
Well, the devil is in the details. The rogue removal of the PIL directory bypassed
the removal of PIL.pth. That pth file is parsed by the
virtualenv custom site.py — ~/.virtualenvs/piltest/lib/python2.7/site.py.
That, in turn, causes the addition of the PIL path in sys.path
which breaks proper Pillow functioning.
A path configuration file is a file whose name has the form <package>.pth; its contents are additional directories (one per line) to be added to sys.path. Non-existing directories (or non-directories) are never added to sys.path; no directory is added to sys.path more than once. Blank lines and lines beginning with
'#'are skipped. Lines starting with'import'are executed.
The fix is to clear out PIL.pth or remove it altogether.
(piltest)site-packages$ cat PIL.pth PIL (piltest)site-packages$ rm PIL.pth
2013-04-15 - brief / dbase backup bonanza
Of course you do daily backups of your data. For your databases, you
generally need a dump of the data for it to be useful.
For your and my reference, here are a few database dump scripts.
Make sure /var/backups is backed up daily.
Observe that we keep extra backups around. I've found that the need to access an old database is far more common than accessing old files (from the backup storage). Keeping them close means quick access in time of need.
You can choose to rotate the backups for every backup run, or you can use weekday-names
to keep older versions. They both have their advantages. Numeric rotation makes it easier
to add an extra backup just before you attempt some operation. The weekday-name method
makes it easier on the file backups: the backup rsync(1) won't need to fetch
the entire backup directory, but only the latest backup.
If 7 backups are too much for you, you can always add this in the mix:
rm -f /somepath/$db.`LC_ALL=C date +%a -d '-3 days' | tr '[:upper:]' '[:lower:]'`.bz2
posgreSQL
Run as postgres user from your crontab. Here we prefer
using /etc/crontab over the crontab(1) program because it is
more likely that /etc is in your backups than /var/spool/cron.
Create /var/backups/postgres with a 0700 file mode
and postgres ownership.
#!/bin/sh
# (OSSO/2013)
day=`LC_ALL=C date +%a | tr '[:upper:]' '[:lower:]'`
for db in `psql -ltAF, | sed -e '/,/!d;s/,.*//;/^template0$/d'`; do
pg_dump $db >/var/backups/postgres/$db.$day.sql &&
rm -f /var/backups/postgres/$db.$day.sql.bz2 &&
bzip2 /var/backups/postgres/$db.$day.sql
done
And did I mention that the postgres data dump structure is so much more convenient than
MySQLs need for --skip-extended-insert when running a diff of a dump?
MySQL
See the remarks in the file about user permissions. If you're not running
Debian or a derivative (Ubuntu), you'll need to tweak the $mysqlargs
as well.
#!/bin/sh
# (OSSO/2013)
# We assume that the debian.cnf user has enough permissions. If it doesn't,
# you may need to add permissions as appropriate. The user needs read access
# to mysql.proc to be able to dump functions and stored procedures.
mysqlargs=--defaults-file=/etc/mysql/debian.cnf
dstpath=/var/backups/mysql
day=`LC_ALL=C date +%a | tr '[:upper:]' '[:lower:]'`
mkdir -p "$dstpath"
chmod 700 "$dstpath"
# If you have a small database, you can consider adding --skip-extended-insert
# to the mysqldump. If you're running a master/slave setup, you can add
# --master-data or --dump-slave to get "CHANGE MASTER TO" statements added.
mysql $mysqlargs -eSHOW\ DATABASES |
sed '-e1d;/^information_schema$/d;/^performance_schema$/d' |
while read db; do
mysqldump $mysqlargs --ignore-table=mysql.event --quick --routines $db \
>"$dstpath/$db.$day.sql" &&
rm -f "$dstpath/$db.$day.sql.bz2" &&
bzip2 "$dstpath/$db.$day.sql"
done
Update 2013-04-22
Added --ignore-table=mysql.event because Percona mysqldump
wanted me to be explicit about dumping the events. You could add --event if you want your
events backed up. See CREATE EVENT syntax
for more information about this cron-like functionality.
MongoDB
#!/bin/sh
# vim: set ts=8 sw=4 sts=4 et ai tw=79:
# (OSSO/2013-2016)
dstpath=/var/backups/mongo
mongoargs= # e.g. "--host 10.42.40.80"
mkdir -p "$dstpath"
chmod 700 "$dstpath"
export LC_ALL=C # use common English days
all_dbs() {
out=`echo 'show dbs' | mongo $mongoargs --quiet`
if test $? -eq 0; then
echo "$out" | sed -rne 's/^([^[:blank:]]+)[[:blank:]].*/\1/p' |
grep -vE '^(exclude_this_db|and_this_db|twiible_harm_celery)$'
else
echo "Could not run 'show dbs' on mongo server" >&2
exit 1
fi
}
dbs_to_dump=`all_dbs` || exit 1
dump_db() {
db="$1"
tmpdst="$dstpath/$db" # use a temp dir near the destination
# Make room for the backups and the backup log.
if ! mkdir "$tmpdst" 2>/dev/null; then
echo >&2
echo "Removing old backup dir ${tmpdst}... " >&2
echo "Did the previous backup fail?" >&2
echo >&2
rm -rf "$tmpdst"
mkdir "$tmpdst"
fi
# Dump, with stderr to templog, because it also outputs
# stuff when there is success and we don't want cron mails on
# success.
temp=`mktemp`
mongodump $mongoargs -o "$tmpdst" -d "$db" >"$tmpdst/dump.log" 2>"$temp"
if test $? -ne 0; then
cat "$temp" >&2
rm "$temp"
return 1
fi
rm "$temp"
# This machine is backupped daily, we rotate by altering the
# filename.
today=`LC_ALL=C date +%a | tr '[[:upper:]]' '[[:lower:]]'`
yesterday=`LC_ALL=C date +%a -d '-1 days' | tr '[[:upper:]]' '[[:lower:]]'`
# Do we need to zip todays/yesterdays backups?
# (There is only yesterday, unless this is the second time we run today.)
for day in $yesterday $today; do
if test -d "$dstpath/${db}.$day"; then
rm -f "$dstpath/${db}.${day}.tar.gz" || return 1
tar zcf "$dstpath/${db}.${day}.tar.gz" -C "$dstpath" \
"${db}.$day" || return 1
rm -rf "$dstpath/${db}.$day" || return 1
fi
done
# We leave our backups unzipped. Tomorrow they'll get zipped.
mv "$dstpath/${db}" "$dstpath/${db}.$today" || return 1
}
ret=0
for db in $dbs_to_dump; do
if ! dump_db $db; then
echo >&2
echo "Dump of $db failed..." >&2
echo >&2
ret=1
fi
done
exit $ret
Update 2015-01-29
Updated the mongo dump to take an optional "--host" parameter and to dump per DB so we can exclude certain DBs.
Update 2016-04-12
Updated it to cope with the additional output that mongodump produces. Quiet is too quiet, but we don't want to spam succesful dumps. Also fixed set -e which doesn't work inside a function.
Elasticsearch
Ok, this backup script is a bit bigger and it will cause a bit of downtime during the dump. In our case, we can live with the 2 minute downtime.
Restoring this dump goes something like this:
- Block access to your elastic server (using a firewall?)
- PUT the metadata:
curl -XPUT "http://localhost:9200/$INDEX/" -d "`cat mappost_$INDEX`" - Replace the old data dir, and restart elastic.
#!/bin/bash
# (OSSO/2013)
# Ideas from: https://gist.github.com/nherment/1939828/raw/46ddf90fdab1b9749327743382a080344a1949a7/backup.sh
# See that script for how to restore the backup as well.
#
# TIP! Restart the graylog server after running this! It may have choked on
# the missing elastic.
INDEX_ROOT_DIR="/var/lib/elasticsearch/YOUR_NAME_HERE/nodes/0/indices"
BACKUPDIR="/var/backups/elastic"
BACKUPDIR_TMP="$BACKUPDIR/tmp"
if ! /etc/init.d/elasticsearch status >/dev/null; then
echo 'Elasticsearch is not running?'
exit 1
fi
mkdir -p "$BACKUPDIR"
chmod 700 "$BACKUPDIR"
rm -rf "$BACKUPDIR_TMP" # make sure we have a clean dir
mkdir -p "$BACKUPDIR_TMP"
INDICES=`ls "$INDEX_ROOT_DIR"`
touch "$BACKUPDIR/begin.stamp"
# We need to stop elasticsearch to get a clean dump of the data.
# To reduce the inconvenience of the downtime, we'll stop and
# start the server for each index.
for index in $INDICES; do
# Backup the index.. this should be lightning fast. This
# metadata is required by ES to use the index file data.
for i in `seq 10`; do
# Retry curl a few times. ES may take a while to start up.
if curl --silent -XGET -o "$BACKUPDIR_TMP/mapping_$index" \
"http://localhost:9200/$index/_mapping?pretty=true"; then
break
fi
sleep $i
done
if ! test -f "$BACKUPDIR_TMP/mapping_$index"; then
echo "Failed to get mapping_$index from ES.. aborting."
exit 1
fi
# Drop first two lines of metadata.
sed -i -e '1,2d' "$BACKUPDIR_TMP/mapping_$index"
# Prepend hardcoded settings.
echo '{"settings":{"number_of_shards":5,"number_of_replicas":1},"mappings":{' \
>>"$BACKUPDIR_TMP/mappost_$index"
cat "$BACKUPDIR_TMP/mapping_$index" >>"$BACKUPDIR_TMP/mappost_$index"
# Stop elasticsearch so we can create a dump. Hope that no one
# has touched the metadata between our metadata fetch and this
# stop.
#date; echo 'elastic is down'
/etc/init.d/elasticsearch stop >/dev/null
rm -f "$BACKUPDIR/$index.tar" # remove old (should not exist)
# Now lets tar up our data files. these are huge, but we're not
# going to be nice, our elastic is down after all.. we zip it
# right away, assuming that less disk writes is faster than less
# cpu usage.
# (Only tar took 3m42 on 3GB of data.)
# (Tar with gz took 4m01.)
# (Gzip with --fast took about 1m40.)
tar c -C "$INDEX_ROOT_DIR" "$index" \
-C "$BACKUPDIR_TMP" "mapping_$index" "mappost_$index" |
gzip --fast >"$BACKUPDIR/$index.tar.gz.temp"
success=$?
# Done? Start elastic again.
/etc/init.d/elasticsearch start >/dev/null
#date; echo 'elastic is up'
if test $success != 0; then
echo
echo 'Something went wrong.. aborting.'
exit 1
fi
# Move the data.
rm -f "$BACKUPDIR/$index.tar.gz"
mv "$BACKUPDIR/$index.tar.gz.temp" "$BACKUPDIR/$index.tar.gz"
done
# Clean up.
rm -rf "$BACKUPDIR_TMP"
touch "$BACKUPDIR/end.stamp"
That's all for today. More some other time.
Update 2015-04-16
Added LC_ALL=C to all `date` calls above.
You want the names to be equal even if you run the job from the console.
2013-04-14 - probook 4510s / high fan speed
So, there have been numerous reports around the internet that the HP ProBook 4510s has fan speed issues.
In my case, the following happens:
- Turn on the laptop: no problem.
- Using the laptop while on AC: no problem.
- Switch on the laptop from suspend mode without AC plugged in: problem!
The fan goes into overdrive and stays there.
It's related to the temperature measurements, somehow. According to the sensors(1)
tool, it's the temp6 value that's off.
# /etc/sensors3.conf
chip "acpitz-virtual-0"
label temp6 "the-problem"
When I fire it up from suspend mode it's supposedly very high:
the-problem: +90.0°C (crit = +110.0°C)
It looks a bit like problem that's mentioned here: Re: Probook 4530s fan noise : DSDT table edition ? Although that post concerns the 4530s and other models.
I also found tools to edit the HP 4530s fan runtime state — 4530s.zip — but those don't fix the problem on the HP 4510s.
Finally I found a usable workaround: CPU load!
I hacked together a little script tries to burn a lot of CPU at once, and believe it or not,
the fan slows down immediately. As soon as your hear that, hit ^C to
exit the script.
Update 2013-04-22
I've noticed that the time it takes to work varies. Once it took a full minute. Sometimes it's done in seconds.
2013-03-21 - python / twisted / exec environment
Does Python Twisted pass the parent environment to child processes?
By default no, but if you pass env=None then it does.
Ergo, default is env={}.
Let's build a quick example. For those unfamiliar with twisted this may provide a quick intro.
import os from twisted.internet import protocol, reactor, utils
This is what we're going to "run":
proc = ['/bin/sh', '-c', 'export']
#kwargs = {'env': None}
kwargs = {}
A quick way to show output and end after the 2 runs.
done = 0
def on_output(data):
global done
print data
done += 1
if done == 2:
reactor.stop()
Spawning a process, the regular way.
class MyProcessProtocol(protocol.ProcessProtocol):
def outReceived(self, data):
on_output(data)
reactor.spawnProcess(MyProcessProtocol(), proc[0], proc, **kwargs)
Spawning a process, the easier way. Observe that you're not supposed
to pass argv[0] explicitly here. Not very intuitive...
deferred = utils.getProcessOutput(proc[0], proc[1:], **kwargs) deferred.addCallback(on_output)
Lastly, fire it up.
reactor.run()
2013-03-20 - python / temporarily blocking signals
There is no way to “block” signals temporarily from critical sections (since this is not supported by all Unix flavors). Says the python signal module manual.
But I'm using Linux, where it is possible to block signals, so I don't think that limitation applies. And it doesn't.
pysigset takes the burden off calling sigprocmask(2)
through ctypes and provides a “pythonic” interface
to temporarily blocking signals in python.
from signal import SIGINT, SIGTERM
from pysigset import suspended_signals
with suspended_signals(SIGINT, SIGTERM):
# Signals are blocked here...
pass
# Any signals that were blocked are now fired.
Get pysigset on github
or through pip:
pip install git+https://github.com/ossobv/pysigset.git
2013-03-16 - darwin / sed / limited regular expressions
For someone who is used to using only GNU sed(1) it may come as a surprise that
some of the metacharacters don't work with sed on other OS'es.
Specifically: sed on Darwin (BSD) does not grok \+, \| and \?
when in basic regular expression mode (the default).
Switching to extended (modern) regular expression isn't a good idea if you're aiming for compatibility,
because the option -E differs from the GNU sed option -r.
Luckily avoiding the metacharacters mentioned shouldn't generally cause more problems than incurring a bit of typing overhead.
Incompatible:
sed -e '/^) / {
s/ ENGINE=\(MyISAM\|InnoDB\)//
s/ AUTO_INCREMENT=[0-9]\+//
}'
Compatible:
sed -e '/^) / {
s/ ENGINE=MyISAM//
s/ ENGINE=InnoDB//
s/ AUTO_INCREMENT=[0-9][0-9]*//
}'
2013-03-12 - callerid in rpid / opensips / kamailio
For reuse, an OpenSIPS/Kamailio snippet to translate commonly used SIP (VoIP) phone Caller-ID (CLI) headers
into a single one (Remote-Party-ID).
It tries these headers in order, to do a best guess of what the caller wants:
P-Asserted-Identity (with Privacy)
P-Preferred-Identity (with Privacy)
Remote-Party-ID
From
Of course you'll have to run the found CLI against an allow list, but this code expects that to be done on the next hop.
route[sub_cli_as_rpid] {
$var(tmp_name) = ""; # (nothing)
$var(tmp_num) = "Anonymous"; # (unknown)
$var(tmp_clir) = 0;
# PAI/PPI-privacy
if (is_present_hf("Privacy")) {
if (!is_privacy("none")) {
$var(tmp_name) = "Anonymous";
$var(tmp_clir) = 1;
}
# RPID-privacy
} else if ($re) {
if ($(hdr(Remote-Party-ID)[0]) =~ ";privacy=" &&
!($(hdr(Remote-Party-ID)[0]) =~ ";privacy=off(;|$)")) {
$var(tmp_name) = "Anonymous";
$var(tmp_clir) = 1;
}
# From-privacy
} else if ($fU == "Anonymous" || $fU == "anonymous" || $fU == "Unavailable") {
$var(tmp_name) = "Anonymous";
$var(tmp_clir) = 1;
}
# PAI-cli
if ($ai) {
$var(tmp_name) = $(hdr(P-Asserted-Identity)[0]{nameaddr.name}); # including dquotes
$var(tmp_num) = $(ai{uri.user});
# PPI-cli
} else if ($pU) {
$var(tmp_name) = $pn; # including dquotes
$var(tmp_num) = $pU;
# RPID-cli
} else if ($re) {
$var(tmp_name) = $(hdr(Remote-Party-ID)[0]{nameaddr.name}); # including dquotes
$var(tmp_num) = $(re{uri.user});
# From-cli
} else {
if ($fn) {
$var(tmp_name) = $fn;
}
$var(tmp_num) = $fU;
# Privacy from fromname?
if ($fn == "Anonymous" || $fn == "\"Anonymous\"" ||
$fn == "anonymous" || $fn == "\"anonymous\"") {
$var(tmp_clir) = 1;
}
}
# Remove all related headers.
remove_hf("Privacy");
remove_hf("P-Asserted-Identity");
remove_hf("P-Preferred-Identity");
remove_hf("Remote-Party-ID");
# Add a single new one.
if ($var(tmp_name)) { pv_printf("$var(tmp_name)", "$var(tmp_name) "); } # add space
if ($var(tmp_clir)) { $var(tmp_clir) = "full"; } else { $var(tmp_clir) = "off"; }
# (We could add "screen=yes" or "screen=no", but that's beyond the
# scope of this.)
append_hf("Remote-Party-ID: $var(tmp_name)<sip:$var(tmp_num)@$si>;privacy=$var(tmp_clir);screen=no\r\n");
}
This was tested with OpenSIPS 1.7, but it should be compatible with newer version and Kamailio as well.
2013-03-10 - extracting dutch words / from aspell
Sometimes it you need a list of words. For example when you need input for CAPTCHA generation.
aspell(1) has lists of words. So extracting some for a Dutch list
of words should be easy.
Requirements:
/var/lib/aspell/nl.rws
aspell-to-wordlist-nl.py
(view)
Output:
abacus
abces
abactis
...
2013-01-19 - extracting cidr ranges / from unstructured text
If you ever want to quickly update a list of IP/mask (CIDR) ranges from a bit of unstructured text, this might come in handy.
For example: I wanted to get my hands on the IPs that Facebook uses.
Various pages list all the IP ranges for the Facebook AS number 32934. For instance:
http://as.robtex.com/as32934.html.
However, they present the info in a not-machine friendly format.
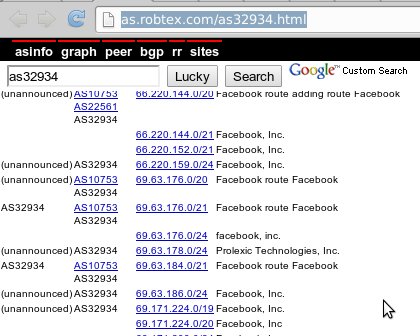
We're not going to type in that list by hand. Instead, we'll use a bit of python. Copy the relevant
bits to stdin of extract_cidr_from_text.py
(view).
$ cat > tmp.txt in bgp route record prefix description (unannounced) AS10753 AS22561 AS32934 66.220.144.0/20 Facebook route adding route Facebook 66.220.144.0/21 Facebook, Inc. 66.220.152.0/21 Facebook, Inc. (unannounced) AS32934 66.220.159.0/24 Facebook, Inc. (unannounced) AS10753 AS32934 69.63.176.0/20 Facebook route Facebook ... et cetera ... ^D
$ cat tmp.txt | python extract_cidr_from_text.py
(
(0x1f0d1800, 0xfffff800), # 31.13.24.0/21
(0x1f0d4000, 0xffffc000), # 31.13.64.0/18
(0x42dc9000, 0xfffff000), # 66.220.144.0/20
(0x453fb000, 0xfffff000), # 69.63.176.0/20
(0x45abe000, 0xffffe000), # 69.171.224.0/19
(0x4a774c00, 0xfffffc00), # 74.119.76.0/22
(0x67046000, 0xfffffc00), # 103.4.96.0/22
(0xadfc4000, 0xffffc000), # 173.252.64.0/18
(0xcc0f1400, 0xfffffc00), # 204.15.20.0/22
)
Voilà! A nice usable python tuple, easy to update whenever the IP address ranges change. Which they do, from time to time.
2013-01-18 - more or less useless tips and tricks 2
More or less useless/useful tips and tricks, bundled together. They weren't worthy of a box div
on their own. I gave them only a li each.
kill -WINCH $$— when your terminal is messed up where the row moves up one line before you've reached the line-length ($COLUMNS):
aSIGWINCHsignal to the current shell will make everything alright again.hash -r— you moved applications around in your$PATHandbashclaims that some applications don't exist in your$PATHeven though you (andls) know that they do:
the hash command will flush the path cache.- Multiple sed expressions can be combined like this:
sed -e '1d;s/abc/def/'— by using a semicolon, or
sed -e '{— by using curlies and line feeds.
1d
s/abc/def/
} - By removing lines with sed you don't need a
grep -vcommand in your Command Line Fu:
sed -e '/HEADER_MATCH/d;s/needle/haystack/'— usually works better than usingsed -nand is more performant than adding separategrepcommands in the mix. Use'/needle/!d'to search instead of delete. - Multiple vim expressions? Use the pipe:
:%s/abc/def/g|%s/foo/bar/g|wn - Inserting vim modelines in lots of files:
find . -name '*.py' | while read x
do [ -s "$x" ] &&
(sed -e '1p;q' "$x" | grep vim: -q ||
sed -i -e '1i# vim: set ts=8 sw=4 sts=4 et ai:' "$x")
done - What's the
ulimit -ccore file block size? It should be 512 bytes. But when called frombashit might be 1024. Soulimit -c 2097152would limit core dumps to max 1GB or 2GB. - Underscores or dashes in Asterisk context names? You'll be looking at
channel names that look like this
Local/some_device@some_context-7f82,1. As you can see, the dash is used already. Prefer the underscore.